dqn에 이어 tf2로 ddpg를 작성해봤다.
tf1이나 keras를 히용해서 ddpg를 작성했을 때 와 달리 tf2의 autograph 덕에 매우 편리했다.
특히 actor를 업데이트하는 부분에서 chain rule을 이용해서 업데이트 하는 부분이 코드로 먼가 깔끔하게 짤 수 있었다.
ddpg 자체가 거의 dqn이 사용한 기법을(target network, replaybuffer) 활용했기 때문에 actor-critic만 잘 구현하면 쉽게 구현할 수 있다.
1. OUNoise
ddpg 에서는 exploration을 위해서 OU noise를 사용한다.
class OUNoise:
def __init__(self, action_dimension, mu=0, theta=0.15, sigma=0.2):
self.action_dimension = action_dimension
self.mu = mu
self.theta = theta
self.sigma = sigma
self.state = np.ones(self.action_dimension) * self.mu
self.reset()
def reset(self):
self.state = np.ones(self.action_dimension) * self.mu
def noise(self):
x = self.state
dx = self.theta * (self.mu - x) + self.sigma * np.random.randn(len(x))
self.state = x + dx
return self.state
OU noise는 github에서 찾아사용했다..
** ounoise
github.com/floodsung/DDPG-tensorflow/blob/master/ou_noise.py
2. Replaybuffer
class ReplayBuffer:
def __init__(self, buffer_size):
self.buffer_size = int(buffer_size)
self.buffer = deque(maxlen=self.buffer_size)
def sample(self, batch_size):
size = batch_size if len(self.buffer) > batch_size else len(self.buffer)
return random.sample(self.buffer, size)
def clear(self):
self.buffer.clear()
def append(self, transition):
self.buffer.append(transition)
def __len__(self):
return len(self.buffer)dqn에서 사용했던 것과 같은 replay buffer 이다
3. Actor
class Actor(tf.keras.Model):
def __init__(self, obs_dim, acs_dim):
super(Actor, self).__init__()
acs_dim = np.squeeze(acs_dim)
self.dense1 = Dense(128, activation='relu', kernel_initializer=tf.keras.initializers.RandomUniform(-1/sqrt(128), 1/sqrt(128)))
self.dense2 = Dense(128, activation='relu', kernel_initializer=tf.keras.initializers.RandomUniform(-1/sqrt(128), 1/sqrt(128)))
self.output_layer = Dense(acs_dim, activation='linear', kernel_initializer=output_init)
self.build(input_shape=(None,) + obs_dim)
self.summary()
def call(self, inputs, training=None, mask=None):
x = self.dense1(inputs)
x = self.dense2(x)
return self.output_layer(x)deterministic policy에 해당하는 부분. dqn은 q-function을 이용해서 greedy selection으로 implicit한 policy를 찾는다면 pg 에서는 policy가 직접 state를 보고 action을 출력한다.
dqn과 다르게 policy 자체를 학습해야하기 때문에 policy를 평가하는 critic을 이용하여 policy improvment를 진행한다.
간단하게 pendulum 환경을 실험할거라서 위와 같이 dense network로 구성하였다. pixel 입력 버전은 추후헤 업데이트 하려구 한다
4. Critic
class Critic(tf.keras.Model):
def __init__(self, obs_dim, acs_dim):
super(Critic, self).__init__()
self.o_dense1 = Dense(128, activation='relu', kernel_initializer=tf.keras.initializers.RandomUniform(-1/sqrt(128), 1/sqrt(128)))
self.o_dense2 = Dense(128, activation='relu', kernel_initializer=tf.keras.initializers.RandomUniform(-1/sqrt(128), 1/sqrt(128)))
self.output_layer = Dense(1, activation='linear', kernel_initializer=output_init)
self.build(input_shape=[(None,) + obs_dim, (None,) + acs_dim])
self.summary()
def call(self, inputs, training=None, mask=None):
obs, action = inputs
z = tf.concat([obs, action], axis=1)
x = self.o_dense1(z)
x = self.o_dense2(z)
return self.output_layer(x)policy를 evaluation 하는 함수. state와 action에 대한 return(culmulative reward) 값을 출력한다.
이 때 state가 pixel input이면 feature extraction해줘야한다 이것도 추후 업데이트
--> actor critic 둘다 논문에서 사용한 hyperparameter를 이용하였다. (hidden - fan in, output - uniform distribution (close to 0))
5. Agent - init
class Agent:
def __init__(self, env, obs_dim, acs_dim, steps,
gamma=0.99, buffer_size=1e6, batch_size=64, tau=0.001):
self.env = env
self.obs_dim = obs_dim
self.acs_dim = acs_dim
self.steps = steps
self.gamma = gamma
self.buffer_szie = buffer_size
self.batch_size = batch_size
self.tau = tau
self.noise = OUNoise(acs_dim)
self.replay_buffer = ReplayBuffer(buffer_size=buffer_size)
self.actor = Actor(obs_dim, acs_dim)
self.actor_target = Actor(obs_dim, acs_dim)
self.critic = Critic(obs_dim, acs_dim)
self.critic_target = Critic(obs_dim, acs_dim)
self.soft_target_update(tau=1) # synchroize target
self.loss_fn = tf.keras.losses.MeanSquaredError()
self.actor_optimizer = tf.keras.optimizers.Adam(lr=0.0001)
self.critic_optimizer = tf.keras.optimizers.Adam(lr=0.001)
하이퍼파라미터, 네트워크, 학습에 필요한 것들을 초기화 했다. actor, critic과 각각의 target network를 만들어주고 파라미터를 일치시키는 작업을 했다. (tau가 1일 때 소프트 업데이트)
ddpg 논문에서 사용한 하이퍼파라미터를 대부분 사용했다. ( tau, batch size, optimizer, optimizer의 lr)
6. Agent - train
def train(self):
global_steps = 0
epochs = 0
rewards_list = []
while global_steps < self.steps:
ob = self.env.reset()
rewards = 0
epoch_step = 0
while True:
ac = self.get_action(ob)
next_ob, reward, done, _ = self.env.step(ac)
transitions = (ob, ac, next_ob, reward, done)
self.replay_buffer.append(transitions)
ob = next_ob
rewards += reward
global_steps += 1
epoch_step += 1
if global_steps >= 4000:
if global_steps == 4000:
print("train start")
transitions = self.replay_buffer.sample(batch_size=self.batch_size)
self.learn(*map(lambda x: np.vstack(x).astype('float32'), np.transpose(transitions)))
self.soft_target_update()
if done:
rewards_list.append(rewards/epoch_step)
print(f"# {epochs} epochs avg reward is {rewards/epoch_step}")
epochs += 1
breaktrain 인터페이스는 dqn과 같다.
7. Agent - learn
@tf.function
def learn(self, ob, ac, next_ob, reward, done):
next_ac = tf.clip_by_value(self.actor_target(next_ob), self.env.action_space.low, self.env.action_space.high)
q_target = self.critic_target([next_ob, next_ac])
y = reward + (1-done) * self.gamma * q_target
with tf.GradientTape() as tape_c: # for train critic
q = self.critic([ob, ac])
q_loss = self.loss_fn(y, q)
grads_c = tape_c.gradient(q_loss, self.critic.trainable_weights)
with tf.GradientTape() as tape_a: # for train actor
a = self.actor(ob)
q_for_grad = -tf.reduce_mean(self.critic([ob, a]))
grads_a = tape_a.gradient(q_for_grad, self.actor.trainable_weights) # grad q / actor_param
self.critic_optimizer.apply_gradients(zip(grads_c, self.critic.trainable_weights))
self.actor_optimizer.apply_gradients((zip(grads_a, self.actor.trainable_weights)))actor와 critic을 번갈아가면서 학습시키는 부분
critic은 td error를 통해 학습을 하고, actor는 dpg 논문대로 policy를 평가하는 critic를 chain rule을 적용하여 학습하게된다.
이 때, 우리의 목표는 maximize Q 가 목표이고, gradient ascent를 진행시켜야 한다. 이 말은 -Q를 minimize하는 과정과 같기 때문에 -tf.reduce_mean(q) 로 목적함수를 바꿔주고 gradient descent를 진행해주면 된당
이 때, tf2는 자동미분을 지원해줘서 연산 순서만 잘 맞춰놓으면 알아서 미분해준다.
tf1에서는 이렇게 구현했었다.
--



keras 에서는 model의 gradient input 값을 주어서 예측 시에는 더미 값을 입력하고, 학습 시에는 gradient를 구해서 입력으로 설정하여 학습시켰던거 같다. 근데.. 코드를 찾아봐도 없다 ㅠ.ㅠ
8. Agent - soft target update
def soft_target_update(self, tau=None):
tau = self.tau if tau is None else tau
actor_tmp = tau * np.array(self.actor.get_weights()) + (1. - tau) * np.array(self.actor_target.get_weights())
critic_tmp = tau * np.array(self.critic.get_weights()) + (1. - tau) * np.array(self.critic_target.get_weights())
self.actor_target.set_weights(actor_tmp)
self.critic_target.set_weights(critic_tmp)논문에서는 학습의 안정성을 위해 (target network가 급격하게 변하는 것을 방지) 천천히 업데이트 하도록 하였다.
get_weights의 리턴 type이 list이기 때문에 상수 값을 곱셈할 때 broadcasting을 지원하지 않는다. np.array로 감싸준다음 broadcasting하도록 바꾸자.
9 result
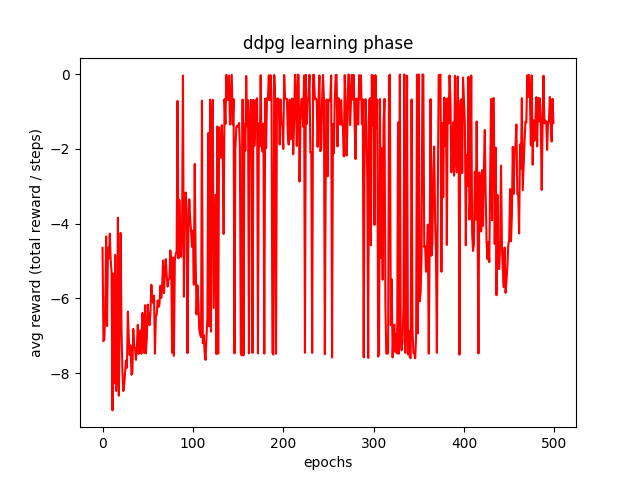
학습 시 epoch 마다의 reward 변화 20~100까지 학습이 잘되구 그이후로 왔다 갔다 한다

학습 후, 학습이 안된 agent와 학습이된 agent의 reward 비교 결과
차이가 꽤 많이 난다.


10. 전체 코드
import random
from collections import deque
from math import sqrt
import gym
from gym import spaces
import numpy as np
import tensorflow as tf
from tensorflow.keras.layers import Conv2D, Dense, MaxPooling2D, Flatten, concatenate
import matplotlib.pyplot as plt
output_init = tf.keras.initializers.RandomUniform(-3*10e-3, 3*10e-3)
# output_init = tf.keras.initializers.RandomUniform(-3*10e-4, 3*10e-4) # pixel
class OUNoise:
def __init__(self, action_dimension, mu=0, theta=0.15, sigma=0.2):
self.action_dimension = action_dimension
self.mu = mu
self.theta = theta
self.sigma = sigma
self.state = np.ones(self.action_dimension) * self.mu
self.reset()
def reset(self):
self.state = np.ones(self.action_dimension) * self.mu
def noise(self):
x = self.state
dx = self.theta * (self.mu - x) + self.sigma * np.random.randn(len(x))
self.state = x + dx
return self.state
class ReplayBuffer:
def __init__(self, buffer_size):
self.buffer_size = int(buffer_size)
self.buffer = deque(maxlen=self.buffer_size)
def sample(self, batch_size):
size = batch_size if len(self.buffer) > batch_size else len(self.buffer)
return random.sample(self.buffer, size)
def clear(self):
self.buffer.clear()
def append(self, transition):
self.buffer.append(transition)
def __len__(self):
return len(self.buffer)
class Actor(tf.keras.Model):
def __init__(self, obs_dim, acs_dim):
super(Actor, self).__init__()
acs_dim = np.squeeze(acs_dim)
self.dense1 = Dense(128, activation='relu', kernel_initializer=tf.keras.initializers.RandomUniform(-1/sqrt(128), 1/sqrt(128)))
self.dense2 = Dense(128, activation='relu', kernel_initializer=tf.keras.initializers.RandomUniform(-1/sqrt(128), 1/sqrt(128)))
self.output_layer = Dense(acs_dim, activation='linear', kernel_initializer=output_init)
self.build(input_shape=(None,) + obs_dim)
self.summary()
def call(self, inputs, training=None, mask=None):
x = self.dense1(inputs)
x = self.dense2(x)
return self.output_layer(x)
class Critic(tf.keras.Model):
def __init__(self, obs_dim, acs_dim):
super(Critic, self).__init__()
self.o_dense1 = Dense(128, activation='relu', kernel_initializer=tf.keras.initializers.RandomUniform(-1/sqrt(128), 1/sqrt(128)))
self.o_dense2 = Dense(128, activation='relu', kernel_initializer=tf.keras.initializers.RandomUniform(-1/sqrt(128), 1/sqrt(128)))
self.output_layer = Dense(1, activation='linear', kernel_initializer=output_init)
self.build(input_shape=[(None,) + obs_dim, (None,) + acs_dim])
self.summary()
def call(self, inputs, training=None, mask=None):
obs, action = inputs
z = tf.concat([obs, action], axis=1)
x = self.o_dense1(z)
x = self.o_dense2(z)
return self.output_layer(x)
class Agent:
def __init__(self, env, obs_dim, acs_dim, steps,
gamma=0.99, buffer_size=1e6, batch_size=64, tau=0.001):
self.env = env
self.obs_dim = obs_dim
self.acs_dim = acs_dim
self.steps = steps
self.gamma = gamma
self.buffer_szie = buffer_size
self.batch_size = batch_size
self.tau = tau
self.noise = OUNoise(acs_dim)
self.replay_buffer = ReplayBuffer(buffer_size=buffer_size)
self.actor = Actor(obs_dim, acs_dim)
self.actor_target = Actor(obs_dim, acs_dim)
self.critic = Critic(obs_dim, acs_dim)
self.critic_target = Critic(obs_dim, acs_dim)
self.soft_target_update(tau=1) # synchroize target
self.loss_fn = tf.keras.losses.MeanSquaredError()
self.actor_optimizer = tf.keras.optimizers.Adam(lr=0.0001)
self.critic_optimizer = tf.keras.optimizers.Adam(lr=0.001)
def train(self):
global_steps = 0
epochs = 0
rewards_list = []
while global_steps < self.steps:
ob = self.env.reset()
rewards = 0
epoch_step = 0
while True:
ac = self.get_action(ob)
next_ob, reward, done, _ = self.env.step(ac)
transitions = (ob, ac, next_ob, reward, done)
self.replay_buffer.append(transitions)
ob = next_ob
rewards += reward
global_steps += 1
epoch_step += 1
if global_steps >= 4000:
if global_steps == 4000:
print("train start")
transitions = self.replay_buffer.sample(batch_size=self.batch_size)
self.learn(*map(lambda x: np.vstack(x).astype('float32'), np.transpose(transitions)))
self.soft_target_update()
if done:
rewards_list.append(rewards/epoch_step)
print(f"# {epochs} epochs avg reward is {rewards/epoch_step}")
epochs += 1
break
plt.plot(rewards_list, 'r')
plt.xlabel('epochs')
plt.ylabel('avg reward (total reward / steps)')
plt.title('ddpg learning phase')
plt.savefig("ddpg_learning_pendulum-v0.png")
self.actor.save_weights("./ddpg_actor/actor", overwrite=True)
plt.close()
def test(self, epochs=50):
global_steps = 0
epoch = 0
rewards_list = []
while epoch < epochs:
ob = self.env.reset()
rewards = 0
epoch_step = 0
while True:
ac = self.get_action(ob, train_mode=False)
next_ob, reward, done, _ = self.env.step(ac)
transitions = (ob, ac, next_ob, reward, done)
self.replay_buffer.append(transitions)
ob = next_ob
rewards += reward
global_steps += 1
epoch_step += 1
# env.render()
if done:
rewards_list.append(rewards/epoch_step)
print(f"# {epoch} epochs avg reward is {rewards/epoch_step}")
epoch += 1
break
plt.xlabel('epochs')
plt.ylabel('avg reward (total reward / steps)')
plt.title('ddpg test phase')
plt.savefig("ddpg_test_pendulum-v0.png")
@tf.function
def learn(self, ob, ac, next_ob, reward, done):
next_ac = tf.clip_by_value(self.actor_target(next_ob), self.env.action_space.low, self.env.action_space.high)
q_target = self.critic_target([next_ob, next_ac])
y = reward + (1-done) * self.gamma * q_target
with tf.GradientTape() as tape_c: # for train critic
q = self.critic([ob, ac])
q_loss = self.loss_fn(y, q)
grads_c = tape_c.gradient(q_loss, self.critic.trainable_weights)
with tf.GradientTape() as tape_a: # for train actor
a = self.actor(ob)
q_for_grad = -tf.reduce_mean(self.critic([ob, a]))
grads_a = tape_a.gradient(q_for_grad, self.actor.trainable_weights) # grad q / actor_param
self.critic_optimizer.apply_gradients(zip(grads_c, self.critic.trainable_weights))
self.actor_optimizer.apply_gradients((zip(grads_a, self.actor.trainable_weights)))
def get_action(self, ob, train_mode=True):
if train_mode:
return np.clip(self.actor(ob[np.newaxis])[0] + self.noise.noise(), self.env.action_space.low, self.env.action_space.high)
else:
return np.clip(self.actor(ob[np.newaxis])[0], self.env.action_space.low, self.env.action_space.high)
def soft_target_update(self, tau=None):
tau = self.tau if tau is None else tau
actor_tmp = tau * np.array(self.actor.get_weights()) + (1. - tau) * np.array(self.actor_target.get_weights())
critic_tmp = tau * np.array(self.critic.get_weights()) + (1. - tau) * np.array(self.critic_target.get_weights())
self.actor_target.set_weights(actor_tmp)
self.critic_target.set_weights(critic_tmp)
if __name__ == '__main__':
env = gym.make('Pendulum-v0')
obs_dim = env.observation_space.shape
acs_dim = None
if isinstance(env.action_space, spaces.Box):
acs_type = 'continuous'
acs_dim = env.action_space.shape
elif isinstance(env.action_space, spaces.Discrete):
acs_type = 'discrete'
acs_dim = env.action_space.n
else:
raise NotImplementedError('Not implemented ㅎㅎ')
agent = Agent(env, obs_dim, acs_dim, 100000)
agent.train()
agent.test()
**
pycharm만 쓰다가 vscode를 쓰고 있는데 프로젝트 폴더 구성하는게 조금 어렵다 ㅠ.
pycharm은 gui로 running cofiguration을 쉽게 설정할 수 있었다. (working directory, script path...)
vscode는 workspace 상의 settings.json의 cwd 파라미터를 통해 working directory를 선택하면 된다고 하는데... 잘 안된당..
replaybuffer, noise, network, agent 부분을 따로 폴더로 관리하고 싶은데... vscode에서 workspace 구성하는 방법을 좀 더 알아봐야겠다.. ^0^
그리구 집에서는 syntax highlithing을 function 단위까지 해주는데 왜 사무실에서는 안될까... 이것도 찾아봐야겠다...
*** vscode marketplace --> pylance 요걸 깔아주면 된당 ㅎㅎ
'연구 > 딥러닝' 카테고리의 다른 글
| [강화학습] tensorflow 2로 DQN (2) | 2021.02.07 |
|---|---|
| [Colab] Colab 빠르게 사용해보기 (0) | 2019.11.15 |
| [cs294-112] 1.Supervised Learning of Behaviors (0) | 2019.08.03 |


